




From Single-Turn RLHF to Temporal Preference Learning
从 Single-Turn RLHF 到 Temporal Preference Learning
TL;DR
We kept running into the same paradox in production: models that score higher on offline single-turn quality don't reliably win on long-horizon A/B metrics—retention, re-engagement, conversation depth. Some models look worse in head-to-head reply comparisons yet keep users talking longer, coming back more often, and opening the app the next day.
This is not evaluation noise. It is objective misalignment: current alignment methods optimize for the reply. Consumer AI needs to optimize for the trajectory.
In assistant use cases, the loop is prompt → answer → done, and treating preference as a per-reply attribute works fine. But in AI companions, interactive fiction, roleplay, and creative collaboration—the consumer AI products where users spend hours, not minutes—what users actually evaluate is a trajectory: Is the persona consistent? Is the narrative advancing? Are promises being honored? Is the emotional arc sustainable? The ultimate vote is not a thumbs-up. It is whether they come back tomorrow.
This paper proposes a shift in the training objective: if we want to train better models for long-horizon consumer AI, we need to move the optimization target from winning the next turn to earning the next session.
We call this Temporal Preference Learning.
1 The Structural Mismatch Between Single-Turn RLHF and Consumer AI
RLHF has become the dominant alignment paradigm for large language models. But it rests on a strong and rarely stated assumption: preference is a property of a single reply. In standard RLHF, this assumption is baked into the entire training objective. Given the same prompt, annotators compare two replies and pick the preferred one; a reward model learns to predict that judgment; the policy is then optimized to generate higher-scoring replies. This works beautifully in assistant settings because the task is nearly single-turn by nature: the user asks, the model answers, and most of the value can be judged within that exchange. Consumer AI products don't work this way. In AI companions, interactive fiction, roleplay, and creative co-authoring, the fundamental unit of value is not a single reply—it is an extended interaction trajectory. A conversation might span 20, 50, or hundreds of turns across multiple sessions. Users gradually form expectations around persona stability, memory continuity, narrative progression, emotional pacing, and promise fulfillment. What they evaluate is no longer "Is this reply good?" but "Is this relationship worth continuing?" This creates a structural optimization mismatch. Single-turn RLHF optimizes for: does this reply win in an isolated comparison? What actually determines long-term value in consumer products are trajectory-level properties: cross-turn consistency, sustainable narrative tension, the ability to deliver on delayed promises, and whether the user keeps investing attention. When the proxy objective diverges from the true objective, the model systematically learns to "win this turn" rather than "sustain the experience." It becomes locally more pleasing but globally more hollow—single-turn scores go up while users lose reasons to keep going.
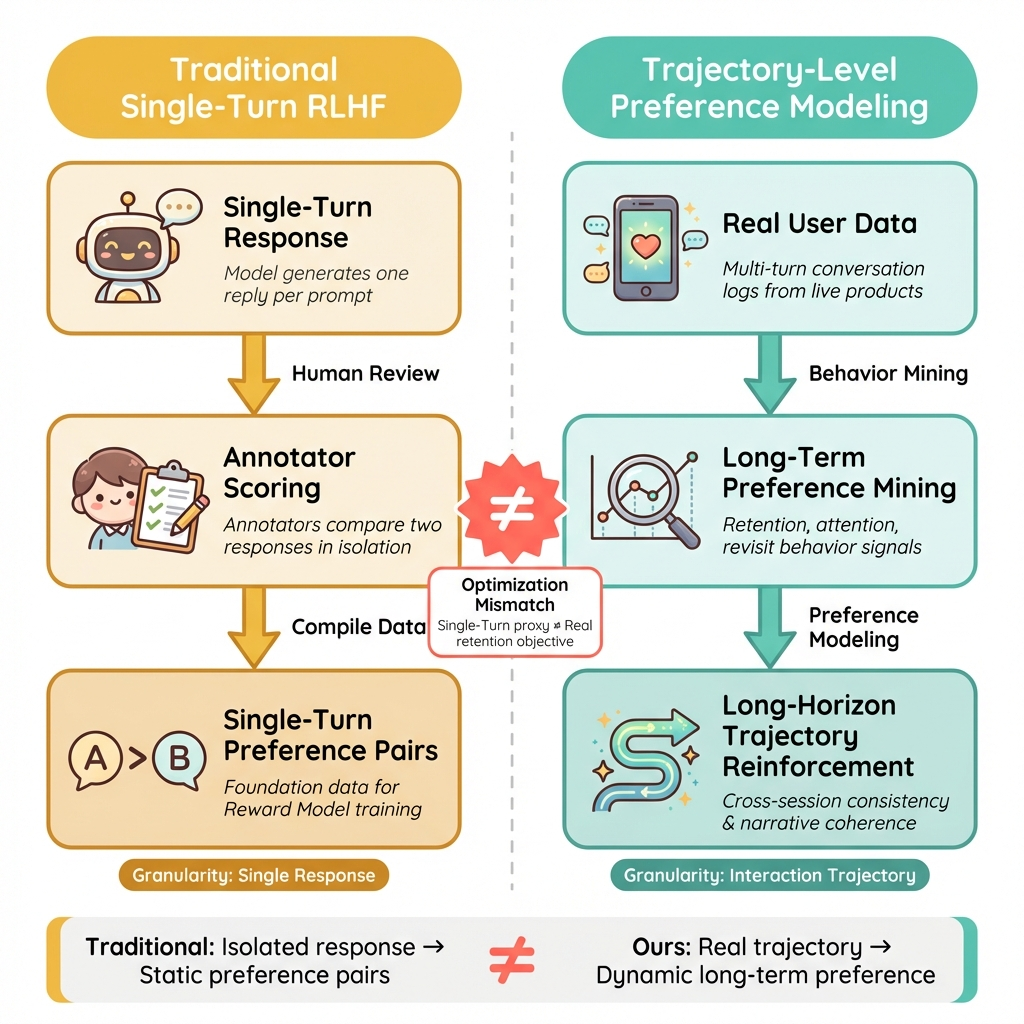
2 Preference Myopia: Four Failure Modes
Preference is not a static label. It is a temporally structured signal. The same reply can shift from "good" to "bad" depending on when it occurs in the trajectory, what preceded it, and what it forecloses.
Why does single-turn alignment systematically fail in long-horizon settings? We call this phenomenon Preference Myopia: the optimization process sees only the current-turn cross-section of preference and is blind to its full temporal structure. In long-horizon interactions, a user's true preference has at least four dimensions:
- Instant gratification — does this turn look good in isolation? (turn-level quality)
- Trajectory momentum — does it make the conversation worth continuing? (narrative momentum)
- Delayed payoff — does it plant hooks that get honored later? (promise fulfillment)
- Temporal decay — is the same stimulus pattern wearing out? (novelty decay)
Of these four, only the first can be directly observed in a single-turn comparison. The other three are inherently temporal. Single-turn preference learning is structurally biased toward what can be redeemed in the current turn: more eloquent phrasing, stronger emotional payoff, more "impressive"-looking text. These win in offline comparisons but overdraw the future—narrative stalls, promises go unfulfilled, personas drift, stimulation overload accelerates fatigue. This is also why we found that the structure of reading speed and dwell time is a better proxy for true preference than thumbs-up/thumbs-down: it carries the dynamics of user attention and naturally encodes both temporal decay and trajectory position.
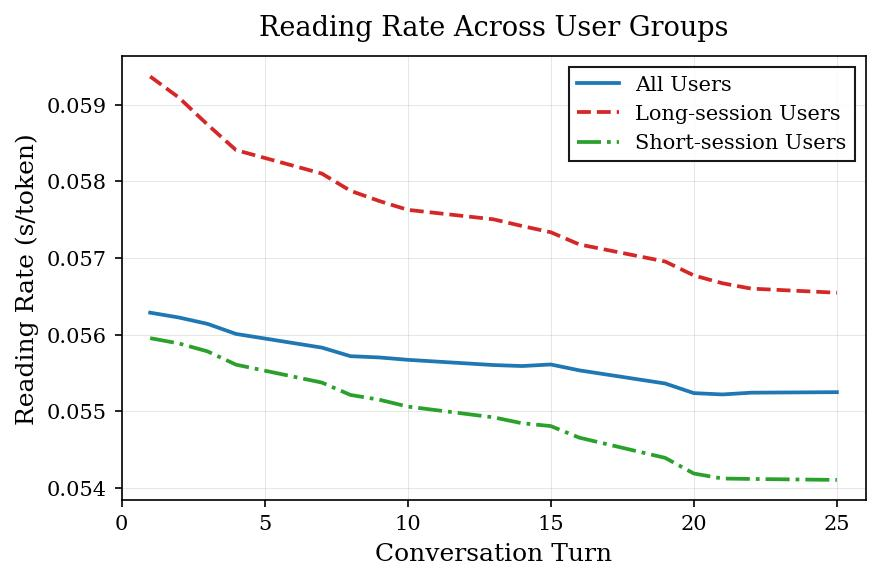
3 What We See in Production at Scale
We observe two stable, reproducible phenomena in a live system with tens of millions of daily active users.
3.1 Offline Ranking Has Unstable Predictive Power for Online Metrics
We rank models by offline single-turn preference (ELO / RM score) and validate against long-horizon online metrics: D1/D7 retention, re-engagement rate, conversation depth, and effective reading time. Intuitively, higher offline rank should predict stronger online performance. It doesn't. The rank correlation between offline ordering and online uplift is unstable, with frequent reversals where the offline winner lands at or below the median online.
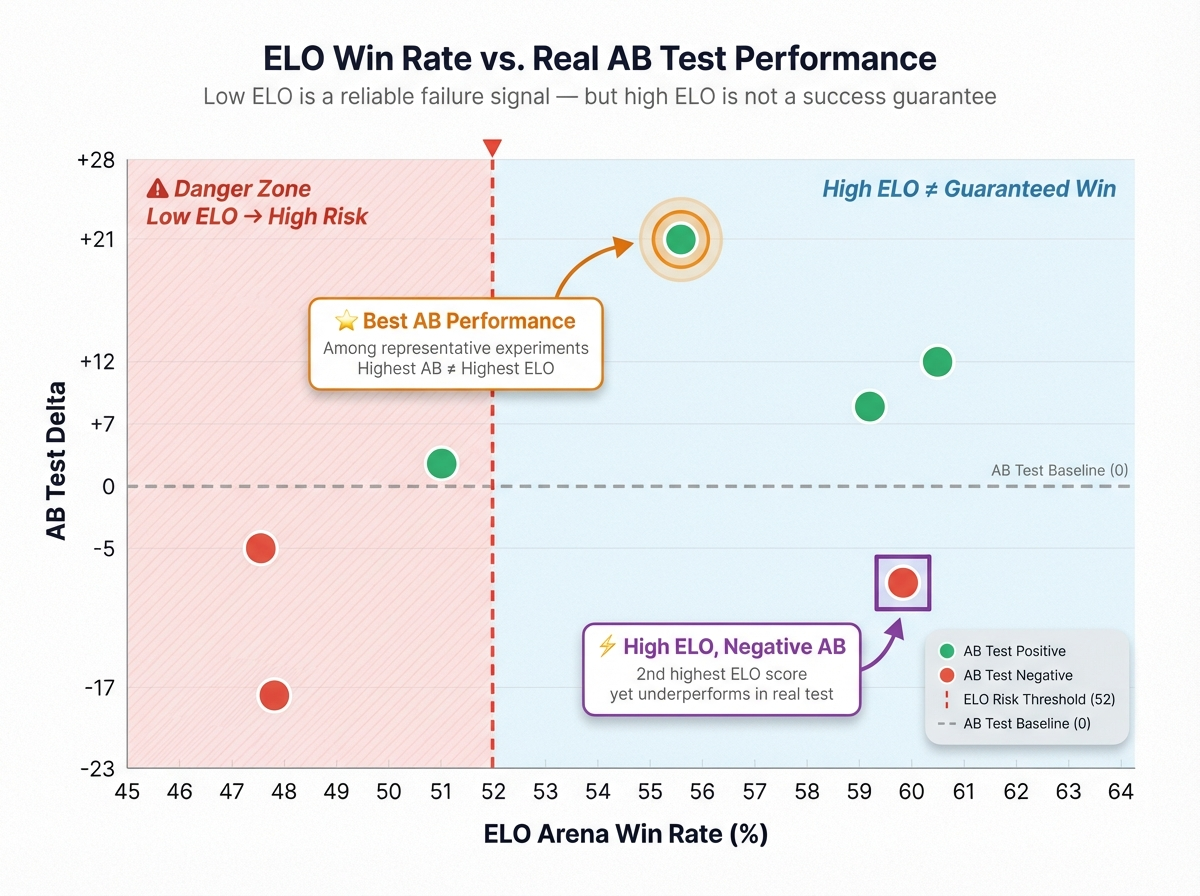
3.2 Introducing Temporal Signals Systematically Improves Long-Horizon Metrics
The mismatch is not intractable. When we incorporate behaviorally grounded temporal signals into the reward—denoised effective reading time, whether the user continues chatting, whether they return—long-horizon online metrics improve systematically. We apply length normalization and anti-gaming constraints so the model cannot score points simply by padding replies or manufacturing shallow engagement. Results from a representative experiment:
| Metric | Uplift | CI |
|---|---|---|
| chat_send | +22.7% | ±1.6% |
| chat_duration | +22.5% | ±1.4% |
| Drop-off Rate | -10.3% | ±3.1% |
| d1_new_user_retention | +5.9% | ±2.3% |
| d3_new_user_retention | +9.2% | ±3.3% |
| d7_new_user_retention | +14.6% | ±3.9% |
When reward learns to see time, the model starts optimizing for long-term value.
4 Temporal Preference Learning
We call this training paradigm Temporal Preference Learning. The core change fits in one sentence:
Upgrade preference supervision from turn-level to trajectory-level, and explicitly model temporal structure.
4.1 Objective: From Per-Turn Reward to Trajectory Return
Let a conversation trajectory be
τ = (s₁, a₁, s₂, a₂, …, s_T, a_T)
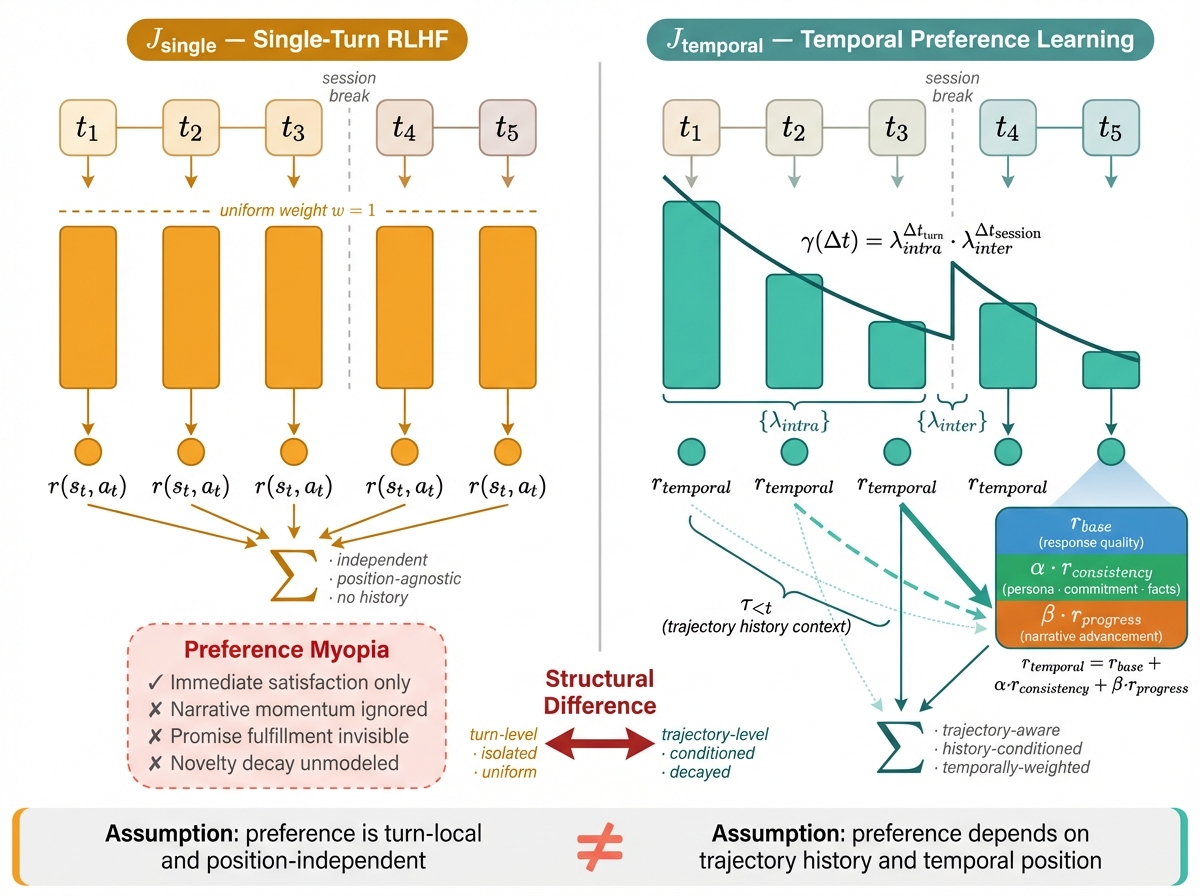
where is the dialogue state at turn (including history) and is the model's reply. The standard single-turn RLHF objective optimizes a simple sum of per-step rewards:
This implicitly assumes that each turn's value can be assessed independently, that the quality of a reply does not depend on its position in the trajectory, and that all turns carry equal weight. In long-horizon consumer conversations, all three assumptions break down. In Temporal Preference Learning, we rewrite the objective as a temporally structured trajectory return:
Two essential differences from single-turn RLHF: First, reward is no longer equally weighted. Different turns contribute differently to the overall experience. Later payoffs, cross-session continuity, and genuine attention all mean that "one point of reward" at different trajectory positions represents different real value. γ(Δt) captures this temporal structure—not as a mechanical step-level discount, but as a function of real elapsed time that treats intra-session and inter-session influence differently. Second, reward is no longer turn-local. r_temporal(sₜ, aₜ, τ_{<t}) does not just evaluate "Is this reply good on its own?" but "Does this reply, placed in this trajectory, make the experience more worth continuing?" This lets the reward model capture properties that single-turn RMs structurally cannot see:
- Promise fulfillment: The hook planted at turn 5—was it paid off by turn 15?
- Persona consistency: Is the character's voice and stance drifting?
- Narrative progress: Is this turn advancing the story, or spinning in place?
- Emotional sustainability: Is the model burning through the user's emotional threshold?
In implementation, this decomposes as: where is baseline reply quality (similar to a standard RM), measures alignment with historical trajectory (persona, promises, facts), measures state advancement, and are tunable weights. Intuition: the unit of reward shifts from "Is this reply good?" to "Does this reply make the trajectory more worth continuing?"
4.2 Data: Trajectory-Segment Preference with Horizon Tags
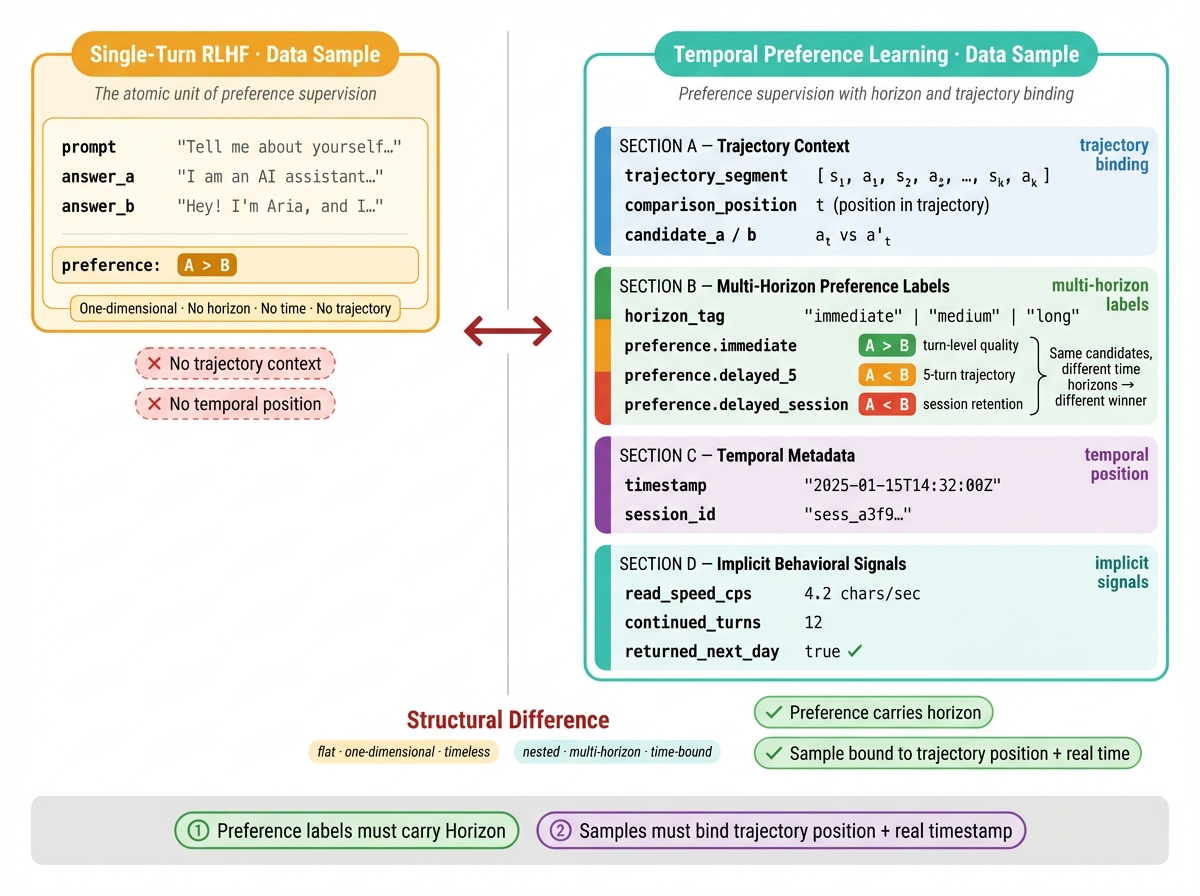
Standard single-turn supervision looks like { prompt, answer_a, answer_b, preference }. Temporal Preference Learning writes temporal structure into the sample itself. The minimal data unit is a horizon-tagged trajectory-segment preference.
The key is not the number of fields. It is two structural requirements: preference labels must carry a horizon tag that distinguishes "immediately pleasing" from "delayed payoff," and samples must be bound to trajectory position and real time—otherwise the model cannot learn preference decay or long-range credit assignment.
4.3 Supervision Signals: Two Scalable Sources of Implicit Preference
With the objective and data structure defined, the key question becomes an engineering one: where do these temporally structured preference labels come from? In production, we rely on two classes of scalable implicit preference, both sharing the same property: they generate comparable differences under maximally similar context, reducing contamination from user engagement level or topic quality.
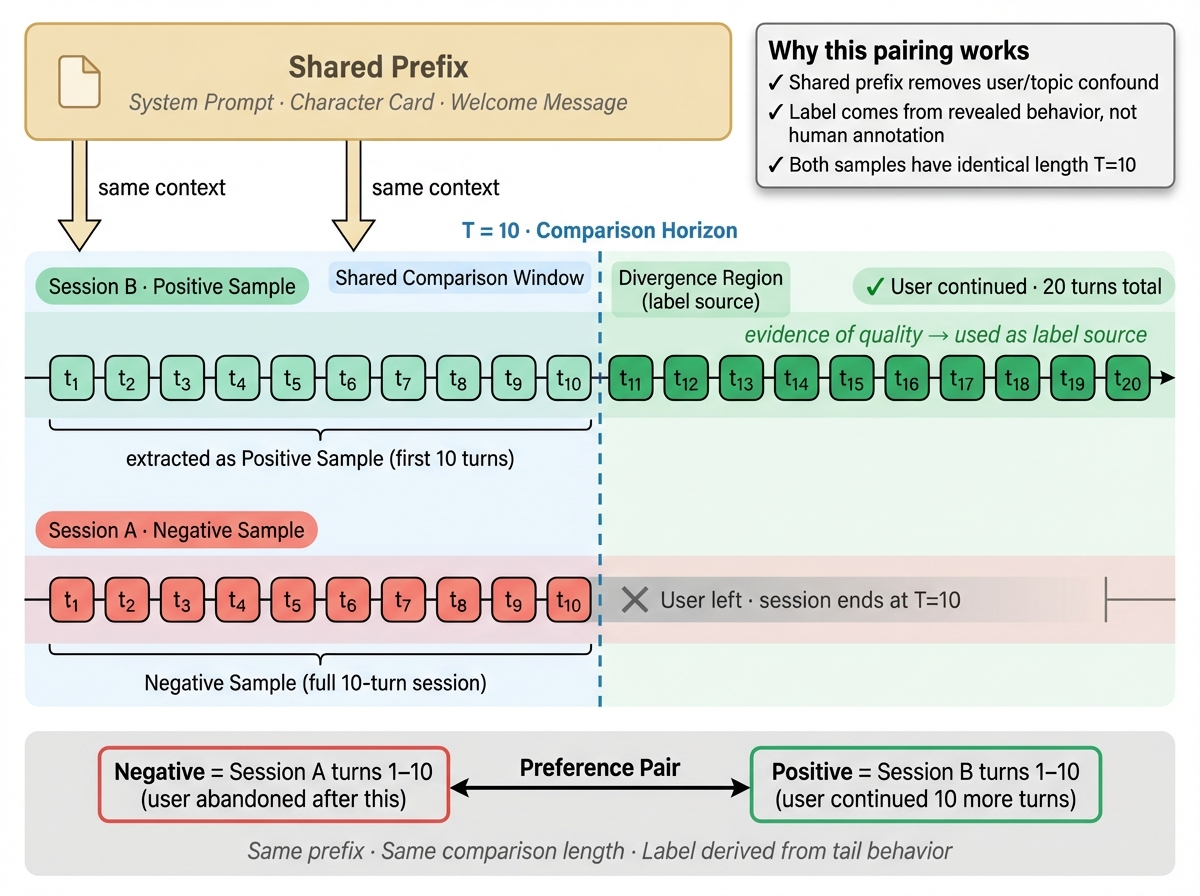
(A) Same-Session Tail Pairing
The first signal comes from within a single session. We take two segments from the same conversation trajectory that share a common prefix but diverge in their tail behavior, and construct a preference pair. Because both samples share the same user, character setup, and most of the preceding context, the difference is primarily attributable to tail-segment quality—allowing us to answer a cleaner question: given the same starting point, which continuation is more worth pursuing? This construction naturally controls for the hardest confounders. Cross-user comparisons are easily contaminated by engagement level, reading habits, and topic preference. Cross-session comparisons get biased by opening quality and character appeal. Same-session tail pairing holds these variables as constant as possible, focusing supervision on whether tail quality is improving, holding, or degrading. In implementation, we combine denoised behavioral time signals (effective reading speed, continued turns, local drop-off, abrupt session termination) to assess tail trajectory quality. To reduce natural variance in reading speed and dwell patterns across users, filtering rules should preferably rely on within-user or even within-session relative percentile comparisons, layered with necessary global absolute thresholds, rather than a single global standard.
(B) Regeneration as a Natural A/B Test
The second signal comes from user-initiated regeneration. When a user asks the model to "try again" in nearly identical context, the system obtains a remarkably clean natural experiment: same user, same context, same intent, explicit re-sampling of model output. The rejected first reply already carries a weak negative signal; the version that subsequently receives continued reading, continued conversation, or better downstream trajectory constitutes a stronger positive candidate. Compared to tail pairing, regeneration offers a more explicit same-condition contrast and is especially useful for learning the link between local reply quality and short-to-medium-term trajectory impact. Its limitation is selection bias—regeneration only occurs when the user cares enough or is dissatisfied enough to trigger it. It is best used as a high-precision supervision source, not the sole one. In practice, a more robust approach is to first score and filter regeneration pairs through a reward model (or temporal RM) before feeding them into DPO, GRPO, or other preference optimization pipelines, rather than using the raw pairs end-to-end. This absorbs noise from logging gaps, instrumentation artifacts, and idiosyncratic user behavior before converting signals into training gradients.
5 Engineering: From Signal to Trainable Gradient
The first risk of incorporating temporal signals is obvious: time can be gamed. A model can pad replies with low-information-density filler to stretch dwell time without creating real value. The engineering goal is not "make sessions longer" but: earn sustainable attention under a quality constraint—reward “worth continuing,” not “continuation itself.” In other words, the core engineering question is: how do we convert “the user stayed longer” into “what the model did right.”
5.1 Denoising: Exit ≠ Failure
Not every session end means the model failed. Users leave for phone calls, completed goals, or natural narrative closure. Treating exit/stay as raw reward contaminates gradients with false negatives. Our first step is separating "natural endings" from the penalty signal:
- Narrative closure detection — identify resolution sequences, farewell patterns, and goal-completion markers.
- Temporal cross-validation — combine click/scroll/dwell distributions with interaction density to filter background dwell, anomalous durations, and low-intent traffic.
- Labeling — only abnormal exits (abrupt departure without narrative closure) are labeled as negative signal; natural endings are excluded from the penalty gradient.
5.2 Credit Assignment: Long-Range Attribution Must Be Controlled
The biggest enemy of long-horizon training is not signal sparsity—it is misattribution. When a trajectory collapses at turn 20, which earlier turn is responsible? A long interaction horizon lets negative feedback propagate freely along the chain, making the model overly conservative and afraid to advance. Our approach: assign failure signal primarily to actions that actually changed the trajectory's direction. We don't ask "which turns appeared in this conversation?" but "which turns introduced significant state transitions, caused consistency breaks, or pushed the trajectory toward a collapse-prone region?" In practice, we use a decay-weighted attribution mechanism with a bounded lookback window that prioritizes high-risk turning points: w(t,t′)=exp(−η⋅d(st′,s+1′))⋅𝟙[break(t′)>δ] where d(sₜ', sₜ'₊₁) measures state drift magnitude (embedding distance) and break(t') detects consistency ruptures (persona shift, promise violation, narrative discontinuity). Only turns with significant drift and a consistency break receive substantial failure weight.
We allow the model to fail. We do not allow misplaced blame to drag the entire trajectory into the penalty.
5.3 Anti-Gaming: Reward Sustainable Attention, Not Padding
Any time-based reward will be exploited unless anti-gaming is designed into the objective itself. Rewarding raw duration drives the model toward verbosity, redundant confirmation, excessive empathy—superficially "sticky" but substantively hollow. Temporal reward must be gated: time enters the gradient only when a quality threshold is met. where gate is a quality gating function: gate(sₜ, aₜ) = σ(q(sₜ, aₜ) − q₀) · penalty(aₜ). Here q(sₜ, aₜ) is an independent quality score (information density, non-repetition, narrative progress), q₀ is a baseline quality threshold, σ is a sigmoid implementing a soft gate, and penalty(aₜ) discounts low-information-gain, repetitive, or template-soothing responses. The intuition is simple: time is not the reward itself, but an amplifier that activates only after quality clears the bar. What we truly reward is not “making the conversation longer,” but earning longer, more stable, and more sustainable attention without sacrificing quality.
Time is not the reward. It is an amplifier that activates only after quality clears the bar.
On the engineering side, we defend on both the training and serving fronts: length normalization and repetition penalties discount filler; progress weighting rewards event advancement, promise fulfillment, and state maintenance over raw conversation length; online guardrails pair primary metrics (retention, return rate) with red-flag monitors (padding rate, complaint rate, regen spikes)—any pattern of "duration up but return rate down" triggers an immediate rollback.
5.4 The Training Loop
Temporal Preference Learning is not a one-shot pipeline. It is a continuously calibrated feedback loop. Once the model starts optimizing temporally structured reward, user behavior, model strategy, and data distribution all shift. Implicit signals that worked under the previous policy may be reinterpreted under the new one. Without a closed loop, reward quickly falls behind policy. We design the system as a continuous iteration cycle:
Logs → Denoise → Horizon Labels → Reward Model → Policy Iteration → Online A/B → Backfill
Every step answers the same question: does the signal currently being optimized still represent real long-term user value? The moment "duration up, retention down" appears, we roll back. The loop exists to keep temporal signals honest.
6 Worked Example: Turning Reading Speed into Temporal Reward
Principles are easy to state. The hard part is grounding them in a concrete signal that is scalable, noise-resistant, and hard to game. Here we walk through reading speed as a complete worked example.
6.1 Starting Point: The Ceiling of Single-Reply Classification
We first used reading speed as a feature in a reward model trained to predict user satisfaction with individual replies. The model successfully learned the relationship between reading speed and preference—confirming sufficient signal-to-noise ratio. But this version had a structural flaw: no pairwise data, so it could only do single-reply classification, not preference ranking.
6.2 Bottleneck: Context Contamination
A more serious problem emerged in deployment. The classifier sees the entire session, and its judgments are heavily influenced by context—especially user query quality. If the first half of the conversation has high user engagement, the model tends to score later replies highly even when reply quality is degrading. Context quality and reply quality become entangled; the model cannot separate them.
6.3 Solution: Same-Session Pairing
The solution comes from TPL's core design. We construct preference pairs within the same session: given a 20-turn conversation where turn 10 meets negative-sample criteria (fast reading speed, declining downstream quality) and turn 20 meets positive-sample criteria (slow reading speed, sustained engagement), the two form a training pair. This simultaneously solves both problems:
- Context contamination eliminated — both samples share the same user, character, and preceding context. The difference comes only from tail-segment quality.
- Natural trajectory scorer — the model is effectively performing quality ranking across positions within the same session, evaluating trajectory quality trends.
6.4 Result
Same-session pairing improved the reward model's offline win rate and delivered a corresponding +2.3% D7 retention uplift online. This validates the core hypothesis of Temporal Preference Learning: temporal signals are not noise. They can be structurally incorporated into preference learning. When the optimization unit upgrades from a single reply to a trajectory, reward model prediction quality improves materially.
7 Conclusion: Optimize Trajectories, Not Turns
Single-turn RLHF taught models to win the current turn. But consumer AI does not win in turns—it wins in trajectories. Users vote with attention, with continuation, with return visits. Failure is rarely one bad reply. It is a slow degradation that single-turn labels never see. Temporal Preference Learning makes a simple claim: optimize trajectories, not turns. Write the time dimension explicitly into the objective function. Let temporal signals enter the gradient—and use denoising, guardrails, and closed-loop calibration to keep them honest. As consumer AI systems grow longer-horizon and more interactive, optimizing single replies will increasingly diverge from the true objective.
When interaction becomes long-horizon, preference inevitably becomes temporally structured. Whoever learns to optimize trajectories first gets closest to the real goal of consumer AI.
TL;DR
我们在生产环境里反复撞到一个悖论:离线单轮质量更高的模型,在长程 A/B(留存、复聊、对话深度)里并不能稳定胜出。有些模型在单条回复比较里看起来更差,却能让用户聊更久、回得更频繁、下一天更愿意打开 App。
这不是评估噪声,而是目标单位错位:当前这一代对齐方法优化的是回复(turn)。消费级 AI 需要优化的是轨迹(trajectory)。
在助手场景里,prompt → answer → done,把偏好当作逐回复属性成立;但在 AI 伴侣、互动小说、角色扮演、创意协作这些消费级长程产品里,用户真正评估的是一条轨迹:人格是否一致、叙事是否能推进、承诺是否兑现、情绪曲线是否可持续。最终投票不是点赞,而是明天会不会回来。
本文提出一个训练标准的迁移:如果要为消费级长程 AI 训练更对的模型,我们就需要把优化目标从 winning the next turn,改成 earning the next session。
我们把这件事叫做:Temporal Preference Learning。
1 Single-Turn RLHF 的核心假设与消费级场景的结构性错位
RLHF 已经成为大语言模型最主流的对齐范式。但它建立在一个很强、也很少被明说的前提上:偏好是单条回复的属性。
在标准 RLHF 流程里,这个前提被写进了整个训练目标。给定同一个 prompt,标注员比较两条回复,选出更偏好的一条;reward model 学习预测这个判断;policy 再去生成更高分的回复。
这套方法在助手型场景里非常有效,因为任务本身就接近单轮闭环:用户提问,模型回答,价值大多可以在这一轮里被判断。
但消费级 AI 产品不是这样工作的。 在 AI 伴侣、互动小说、角色扮演、创意协作中,价值的基本单位不是一条回复,而是一段延展的交互轨迹。一段对话可能跨越 20、50、上百轮,延伸多个 session。用户会逐渐对人格稳定性、记忆连续性、叙事推进、情绪节奏和承诺兑现形成预期。
他们评估的也不再是“这句话好不好”,而是“这段关系值不值得继续”。
这就产生了一个结构性的优化错位:single-turn RLHF 优化的是:这条回复在孤立比较中是否更讨喜。而消费级产品真正决定长期价值的,是轨迹级属性:跨回合一致性、可持续的叙事张力、延迟兑现的能力,以及用户是否愿意把注意力继续投入下去。一旦代理目标和真实目标不一致,模型就会系统性地学会“赢下这一轮”,而不是“经营整段体验”。它可以在局部更讨好,却在长期更空洞;可以让单轮评分上升,却让用户更快失去继续聊下去的理由。
2 Preference Myopia:偏好近视的四重机制
偏好不是一个静态标签,而是一个带时间结构的信号。同一句话在不同时间点、不同轨迹位置、不同历史上下文中,其"好坏"会发生系统性变化。
为什么 single-turn 对齐会在长程场景中系统性失效?我们把这种现象称为 Preference Myopia(偏好近视):优化过程只看到当前回合的偏好切面,看不到偏好在时间轴上的完整结构。在长程交互里,用户的真实偏好至少包含四个维度:
- 即时满足——这一轮看起来不错(turn-level quality)
- 轨迹推进——它是否让对话更想继续(narrative momentum)
- 延迟兑现——它是否为后续埋了钩子,并在未来兑现(promise fulfillment)
- 时间衰减——同一种刺激/套路会迅速疲劳(novelty decay)
这四个维度里,只有第一个可以被单轮比较相对直接地观察到。后面三个,本质上都依赖时间。单轮偏好学习天然偏向可在"当前回合"兑现的东西:更会说、更多情绪价值、更强即时爽感、更长更像"好回答"的文本。这些在离线比较里容易赢,但会透支未来——叙事不前进、承诺不兑现、人格漂移、刺激过载导致疲劳加速。
这也是为什么我们发现阅读速度/停留时间的结构比"点赞/点踩"更像真实偏好:它带着用户注意力的动态变化,天然包含了时间衰减与轨迹位置的信息。
3 来自千万级用户的数据现象
我们在千万级日活的线上系统中观察到两个稳定且可复现的现象:
3.1 离线排序对线上指标的解释力不稳定
我们用离线单轮偏好(ELO / RM score)对模型排序,并用线上长期指标(D1/D7 留存、复聊率、对话深度、有效阅读时长)做对齐检验。按直觉,离线排名越高的模型,线上长期表现也应该越好;但实际情况并不是这样。结果是:离线排序对线上 uplift 的 rank correlation 不稳定,频繁出现"离线第一、线上中位甚至更差"的反转。
3.2 引入时间信号后,长期指标显著改善
更关键的是,这种错位并不是无解的。当我们把带时间结构的行为信号纳入奖励后,长期线上指标出现了系统性改善。
具体来说,我们不再只依赖单轮显式偏好,而是将去噪后的用户行为时间信号——例如有效阅读时长、是否继续聊天、是否回访——作为 temporal reward 的一部分,并在训练中加入长度归一化和反作弊约束,避免模型仅靠灌水、拖长回复或制造表面互动来“刷分”。
结果很明确:
引入时间信号后,模型不仅在互动指标上提升明显,也在留存指标上表现更好,而且这种提升在跨版本实验中更稳定。当 reward 开始看到时间,模型才开始为长期价值负责。
| 指标 | Uplift | CI |
|---|---|---|
| chat_send | +22.7% | ±1.6% |
| chat_duration | +22.5% | ±1.4% |
| Drop-off Rate | -10.3% | ±3.1% |
| d1_new_user_retention | +5.9% | ±2.3% |
| d3_new_user_retention | +9.2% | ±3.3% |
| d7_new_user_retention | +14.6% | ±3.9% |
4 Temporal Preference Learning
我们把这套训练范式称为 Temporal Preference Learning。它的核心改动可以概括为一句话:
核心改动只有一句话:把偏好监督从 turn-level 升级为 trajectory-level,并显式建模时间结构。
4.1 目标函数:从回合奖励到轨迹回报
设一段对话轨迹为:
τ = (s₁, a₁, s₂, a₂, …, s_T, a_T)
其中 sₜ 为第 t 轮的对话状态(包含历史上下文),aₜ 为模型在第 t 轮生成的回复。
Single-turn RLHF 的标准目标函数优化的是逐步 reward 的简单求和:
这里的隐含假设是: 每一轮的价值可以被独立评估;同一条回复的好坏,不依赖它在整条轨迹中的位置;所有回合的 reward 在目标函数里权重相同。但在长程消费级对话里,这三个假设都不成立。
因此,在 Temporal Preference Learning 中,我们把目标改写为带时间结构的轨迹回报:
这一定义相比 single-turn RLHF 有两个本质区别。
第一,reward 不再等权。
不同回合对整条体验的贡献并不相同。越靠后的兑现、跨 session 的延续、以及用户注意力的真实停留,都意味着“同样一分 reward”在不同位置上代表的价值并不一样。
γ(Δt) 用来表达这种时间结构:它不是按固定步长机械折扣,而是根据真实时间间隔,对 session 内与 session 间的影响进行不同处理。
第二,reward 不再只看当前这一轮。
r_temporal(sₜ, aₜ, τ_{<t}) 不只是评估“这句本身好不好”,而是评估“这句放在这条轨迹里,是否让整段体验变得更值得继续”。 这使 reward model 可以开始刻画那些 single-turn RM 很难看到的属性,例如:
- 承诺兑现:第 5 轮挖的坑,第 15 轮是否填上了?
- 人格一致性:角色的语气/立场是否在漂移?
- 叙事推进:这一轮是在推动情节,还是在原地打转?
- 情绪曲线可持续性:是否在透支用户的情绪阈值?
从实现上,我们可以把它理解为:
其中:
- r_base 为基础回复质量(类似标准 RM 的打分)
- r_consistency 衡量与历史轨迹的一致性(人格、承诺、事实)
- r_progress 衡量状态推进(叙事是否向前移动)
- α, β 为可调权重
直觉理解:reward 的单位从"这句好不好"变成"这句是否让轨迹更值得继续"。
4.2 数据结构:带 Horizon 的轨迹片段偏好
Single-turn 的监督数据通常是:
Plain Text{ prompt, answer_a, answer_b, preference }
Temporal Preference Learning 需要把时间结构写进样本,最小数据单元是"带 horizon 的轨迹片段偏好":
Plain Text{ trajectory_segment: [s₁, a₁, s₂, a₂, ..., sₖ, aₖ], // 轨迹片段 comparison_position: t, // 在轨迹中的比较位置 candidate_a: aₜ, // 候选回复 A candidate_b: a'ₜ, // 候选回复 B horizon_tag: "immediate" | "medium" | "long", // 偏好的时间范围 preference: { immediate: A > B, // 即时偏好(当轮表现) delayed_5: A < B, // 5 轮后的轨迹质量 delayed_session: A < B // session 级结果(留存/回访) }, timestamp: "2025-01-15T14:32:00Z", // 真实时间戳 session_id: "...", // 用于同 session 配对 implicit_signals: { read_speed_cps: 4.2, // 阅读速度(字符/秒) continued_turns: 12, // 后续继续轮数 returned_next_day: true // 次日是否回访 }}
关键不在字段多,而在两件事:
- 偏好标签必须带 Horizon:区分"即时讨喜"与"延迟兑现"
- 样本必须绑定轨迹位置与真实时间:否则无法学习偏好衰减与长程信用分配
4.3 监督信号来源:可规模化的两类 Implicit Preference
定义了目标函数和数据结构之后,关键问题变成工程问题:这些带时间结构的偏好监督从哪里来?我们在生产系统里主要依赖两类可规模化的 implicit preference,它们都满足同一个特性:在尽可能相同的上下文下产生可比较的差异,从而减少"用户投入度/话题质量"对标签的污染。
(A) Same-Session Tail Pairing:同一 Session 内构造轨迹对照
第一类信号来自同一个 session 内部。
我们在同一条对话轨迹中,截取共享前缀、但尾部走势不同的两个片段,并把它们构造成一个 preference pair。由于这两个样本共享相同的用户、角色设定和大部分前期上下文,差异主要来自轨迹尾部本身的质量变化,因此可以更干净地回答一个问题:在相同起点下,哪一种后续走势更值得继续。
这种构造方式有一个重要优点:它天然控制了大量最难处理的混杂因素。
跨用户比较时,标签很容易被用户活跃度、阅读习惯、题材偏好所污染;跨 session 比较时,又容易被开场质量、角色吸引力和话题选择带偏。
而 same-session tail pairing 尽可能把这些变量固定住,把监督重点收缩到“尾部质量是否在改善、维持还是恶化”。
在具体实现上,我们通常会结合去噪后的行为时间信号来判断尾部走势,例如有效阅读速度、后续 continued turns、局部 drop-off、以及后续是否快速结束等。为了减少用户之间阅读速度和停留模式的天然差异,筛选规则应尽量基于同用户、甚至同 session 内的相对分位比较,再叠加必要的全局绝对阈值,而不是直接使用单一的全局标准。
(B) Regeneration:用户主动触发的同上下文对照实验
第二类信号来自用户主动触发的 regeneration。
当用户在几乎相同的上下文下要求模型“重来一次”“再生成一版”时,系统实际上获得了一个非常珍贵的自然实验:同一个用户、同一段上下文、同一个意图,对模型输出做了显式再采样。
这类数据的价值非常高,因为它比普通日志更接近真正的 pairwise preference setting。
第一次回复之所以没有被接受,本身就已经包含了一个弱负反馈;而后续被用户继续阅读、继续对话、或者带来更好后续走势的版本,则构成了更强的候选正样本。
和 Same-Session Tail Pairing 相比,Regeneration 的优势在于:
它提供了更明确的“同条件下不同回答”的对照关系,因此更适合用来学习局部回复质量与短中期 trajectory impact 之间的联系。
它的局限则在于,用户触发 regeneration 本身带有选择性偏差——只有当用户足够在意、或者当前回复足够不满意时,才会出现这个动作。
因此,这类信号更适合作为高精度监督源,而不是唯一监督源。
在训练上,一个更稳妥的做法通常不是把这些 pair 直接端到端喂给 DPO,而是先经过 RM 或 temporal RM 做统一打分与过滤,再从多次采样结果中选择更可靠的 pair,最后进入 DPO、GRPO 或其他 preference optimization 流程。
这样可以把线上日志里的噪声、埋点缺失和偶发行为异常先消化掉,再转成更稳定的训练梯度。
5 工程落地:从信号到可训练的梯度
把时间信号纳入训练的首要风险很直接:时间可以被博弈。模型可以用冗长、低信息密度的回复拉长停留,却不创造真实价值。所以工程落地的目标不是"让时长变大",而是:在质量约束下赢得可持续注意力——奖励的是"值得继续",不是"继续本身"。换句话说,工程问题的本质是: 如何把“用户待得更久”转化为“模型做对了什么”。
5.1 去噪:退出 ≠ 失败
不是每次 session 结束都意味着模型失败。用户离开可能是来了电话、达成目的、或自然收束。把"退出/停留"直接当 reward,会用大量假负例污染梯度。我们做的第一件事是把"自然结束"从惩罚里剥离出来:
- 叙事收束标记:识别叙事解决、告别序列、目标完成等 End-of-Story patterns
- 时序交叉验证:结合点击/滚动/停留分布与交互密度,过滤后台停留、异常时长、低意图流量
- 区分标记:异常退出(无收束的离开)才标记为负向信号;自然结束从惩罚梯度中排除
5.2 信用分配:长程归因必须可控
长程训练最大的敌人不是信号稀疏,而是错误归因。轨迹在第 20 轮崩溃时,哪个更早的轮次该负责?长交互 horizon 让"负反馈"很容易沿链条扩散,导致模型变得保守、避免推进。
我们的做法是:只把失败信号重点分配给那些真正改变了轨迹方向的 action。 我们不问“哪些轮次在这段对话里出现过”,而是问:
- 哪些轮次引入了显著的状态跃迁
- 哪些轮次造成了一致性断裂
- 哪些轮次把轨迹推向了之后更容易崩溃的位置
在实现上,我们使用一个衰减加权的归因机制,把失败的影响限制在一个有限回溯窗口内,并优先分配给“高风险转折点”附近的动作。形式上,可以写成:
w(t,t′)=exp(−η⋅d(st′,s+1′))⋅𝟙[break(t′)>δ]
其中:
- t' 是回溯窗口 [t-n, t] 内的历史轮次
- d(sₜ', sₜ'₊₁) 衡量第 t' 轮前后的状态漂移幅度(embedding distance)
- break(t') 检测第 t' 轮是否存在一致性断裂(人格偏移、承诺违背、叙事断裂)
- η 控制衰减速率,δ 为断裂检测阈值
- 只有在状态发生显著漂移且存在一致性断裂的轮次,才会被分配较高的失败权重
我们允许模型犯错,但不允许"错误的 blame"把整段轨迹一起拖下水。
5.3 防博弈:奖励可持续注意力,不奖励灌水
任何基于时间的 reward 都会被策略利用,除非把"反作弊"设计成目标的一部分。只奖励时长,会驱动模型拖沓、重复确认、过度共情——看起来更"黏",但实际价值更低。因此 temporal reward 必须是 gated 的:时间只在质量门槛通过时才进入梯度。
Gated Temporal Reward 的形式化表达:
其中 gate 是一个质量门控函数:
- q(sₜ, aₜ) 为独立的质量评分(回复信息密度、非重复度、推进度)
- q₀ 为质量基线阈值
- σ 为 sigmoid 函数,实现软门控
- penalty(aₜ) 为灌水惩罚项,对低信息增益、重复结构、模板化安抚做折扣
这个目标的直觉很简单:
时间不是奖励本身,而是质量通过之后才能兑现的放大器。因此,我们真正奖励的不是“把对话拖长”,而是在不牺牲质量的前提下,赢得更长、更稳、更可持续的注意力。
在工程上,我们同时在训练侧和线上侧做防御:
- 长度归一 / 重复惩罚:对低信息增益、重复结构、模板化安抚做折扣
- 推进权重:对"事件推进/承诺兑现/状态保持"加权,避免只拉长对话
- 在线护栏:主指标(留存、回访)+ 护栏(灌水、投诉、重复、regen 异常上升);一旦出现"时长涨但回访跌",立即回滚
5.4 训练闭环
Temporal Preference Learning 不是一次性流水线,而是一个持续校准的闭环:一旦模型开始优化时间结构 reward,用户行为、模型策略和数据分布都会随之变化。原本有效的 implicit signal,可能在新策略下被重新解释;如果没有闭环,reward 很快就会落后于策略。
因此,我们把训练系统设计成一个持续迭代的反馈回路,而不是一次性离线训练 Logs → Denoise → Horizon Labels → Reward Model → Policy Iteration → Online A/B → Backfill
这个闭环中,每一步都不是独立模块,而是在共同回答同一个问题:当前被优化的信号,是否仍然代表真实的长期用户价值。一旦出现"时长涨但留存跌",立即回滚。闭环的目的是让时间信号持续、可控地进入梯度——优化可持续的用户价值,而不是可被利用的表面指标。
6 实证:阅读速度如何变成 Temporal Reward
原则容易讲,难的是落到具体信号上:既可规模化、又抗噪声、还不容易被策略博弈。下面用阅读速度(reading speed)作为 worked example,展示 temporal reward 从日志到训练闭环的完整路径。
6.1 起点:单条分类的天花板
第一步是把 reading speed 作为特征训练 reward model,预测用户对单条回复的满意度。模型成功学到了阅读速度与偏好之间的关系——证明这个信号有足够的信噪比。但这个版本有一个结构性缺陷:没有成对数据,无法构成 preference pair,只能做单条分类而非偏好排序。
6.2 瓶颈:上下文污染
更严重的问题出现在部署中。分类模型看到的是整段 session,判断会被上下文——尤其是 user query 的质量——强烈影响。如果前半段用户投入度高,模型会倾向给后半段的回复也打高分,即使回复质量已经在退化。上下文质量和回复质量纠缠在一起,模型无法区分。
6.3 解法:同 Session 配对
解决方案来自 TPL 的核心思路。我们在同一个 session 内构造 preference pair:假设一段对话有 20 轮,其中第 10 轮满足负样本条件(阅读速度快、后续质量下降),第 20 轮满足正样本条件(阅读速度慢、用户持续投入),两条数据构成一个 pair 训练。这同时解决了两个问题:
- 消除上下文污染——两条样本来自同一段对话,共享相同的用户、角色、前期上下文。差异只来自轨迹尾部的质量变化
- 天然的轨迹评分器——模型本质上在对同一 session 内的不同位置做质量排序,评估的是轨迹质量走势
6.4 结果
这种改造带来了明确收益。同 session 配对训练将 reward model 的离线胜率提升了,并带来了+2.3% D7留存相应的线上收益。
这个结果验证了 Temporal Preference Learning 的核心假设:时间信号不是噪声,它可以被结构化地纳入偏好学习;当优化单位从单条回复提升到轨迹时,reward model 的预测质量会显著改善。
7 结语:优化轨迹,而非回合
Single-turn RLHF 教会了模型赢下当前这一轮。但消费级 AI 不是在回合中取胜——而是在轨迹中取胜。用户用注意力投票,用继续投票,用回访投票。失败很少是一条坏回复,而是一场 single-turn 标签永远看不见的慢性退化。
Temporal Preference Learning 的主张很简单:优化轨迹,而非回合;把时间维度显式写入目标函数;让时间信号进入梯度——并用去噪、护栏和闭环校准确保它们的诚实。
随着消费级 AI 系统变得更长程、更交互,优化单条回复将越来越偏离真正的目标。
当交互变成长程,偏好就一定会变成时间结构化的。
谁先学会优化轨迹,谁就更接近消费级 AI 的真正目标。